5. Associations de un à plusieurs▲
5-1. Associations de un à plusieurs entre types d'entités indépendantes▲
5-1-1. Entité-type indépendante (rappel)▲
MySQL Workbench permet d'exprimer au niveau logique un concept important, celui d'entité forte,
indépendante (cf. paragraphe 1.2).
Rappelons qu'une entité (instance) est indépendante (forte, autonome) si son existence ne dépend
pas de façon permanente et définitive de celle d'une autre entité.
Par exemple, chez Dubicobit, un dépôt n'est pas forcément lié sa vie durant à une même région
commerciale, il peut changer d'affectation dans le temps,
tandis que la suppression d'une région
n'entraînera pas celle des dépôts qui la desservent (pour arriver à supprimer une région il aura
donc fallu préalablement rattacher ses dépôts à une autre région).
Structure des données en amont, version MCD merisien :
Une région peut être desservie par plusieurs dépôts et un dépôt dessert exactement une région.
.png)
Version diagramme de classes :
.png)
5-1-2. Icône « 1:n Non-Identifying Relationship »▲
Au niveau MLD, avant qu'on associe DEPOT et REGION, la situation est la suivante :

On sélectionne l'icône « 1:n Non-Identifying Relationship », puis on clique successivement
sur les objets DEPOT et REGION (dans cet ordre, c'est-à-dire le référençant d'abord, puis
le référencé). Au résultat :
.png)
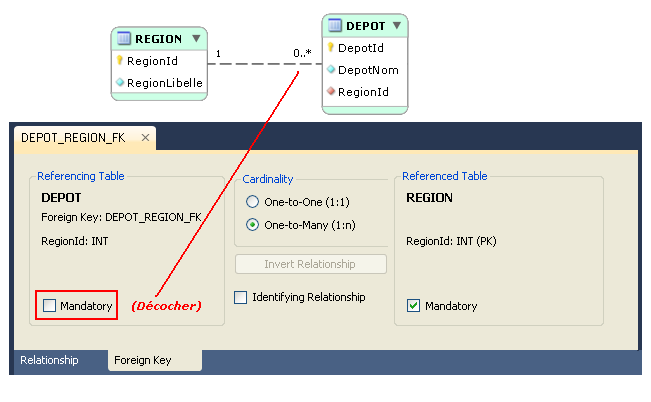
La patte entre DEPOT et REGION est en pointillés : c'est la façon qu'a
l'outil de signaler que DEPOT n'est pas une propriété (multivaluée) de REGION.
DEPOT et REGION sont bien des types d'entités fortes, indépendantes (kernels)
au sens de Codd, et DEPOT se contente de désigner REGION.
Comme une région n'est pas nécessairement desservie par un dépôt, la cardinalité 1,N est à remplacer
par 0,N (décocher la case « Mandatory » du côté DEPOT (Referencing Table)) :
5-2. Associations de un à plusieurs (entre entités-types fortes et dépendantes)▲
5-2-1. Associations binaires▲
5-2-1-1. A la vie à la mort▲
Supposons qu'en amont du MLD, au niveau conceptuel, on ait les règles de gestion des
données suivantes relatives aux commandes des clients :
RG330 : Un client a pu passer plusieurs commandes d'articles.
RG331 : Une commande est passée par exactement un client (c'est-à-dire un et un seul).
RG332 : Une ligne de commande fait référence à exactement un article.
Quand une commande est passée par un client, disons Fernand, elle lui est attachée de manière exclusive,
c'est « à la vie, à la mort », elle n'est pas transférable au client Raoul,
et la suppression de Fernand devrait en théorie entraîner celle de ses commandes.
Une commande devrait donc être considérée comme une entité faible (cf. paragraphe 1.3)
relativement au client auquel elle est attachée, mais, à défaut de procéder par historisation
ou tactique de ce genre, on joue l'exception
qui confirme la règle, à savoir qu'on ne supprime pas un client qui a des commandes
en cours, il ne faudrait surtout pas jouer un vilain tour à l'utilisateur
(« Où sont passées mes commandes ? »)
Pour mettre en évidence cette situation de rattachement exclusif de ses commandes à Fernand,
on pourra utiliser l'identification relative, tout en notant bien qu'il ne sera
pas possible de supprimer un client tant qu'il aura des commandes (sous-entendu : en cours).
La situation initiale :
5-2-1-2. Identification absolue / relative▲
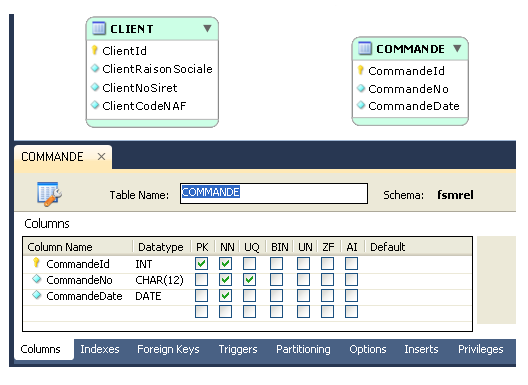
Ci-dessus, la table COMMANDE a pour clé primaire {CommandeId} et pour clé alternative {CommandeNo}.
Par hypothèse, la colonne CommandeNo représente le numéro de commande, lequel doit être unique,
mais c'est aussi une propriété naturelle de la commande et sa structure est du ressort de l'utilisateur.
Dans ces conditions, il est nécessaire de disposer d'une clé
invariante et non significative, c'est-à-dire dont le contrôle échappe à l'utilisateur, d'où la
mise en œuvre pour cela de la colonne CommandeId, correspondant à une propriété artificielle.
On peut en rester là si on se cantonne à l'identification
« absolue » de COMMANDE, mais on peut aussi identifier COMMANDE relativement à CLIENT :
il en résulte un glissement sémantique, mais on résout ainsi une très grande majorité des problèmes
liés aux contraintes de chemin comme dans l'exemple
des devis et des factures.
Au-delà de la modélisation pure, cela peut
aussi aider le DBA à résoudre des problèmes de performance observés au cours des travaux de prototypage
(récupération par exemple de toutes les commandes de tel client), de stratégie de sauvegarde,
toutes choses pour lesquelles le choix de l'index dit
cluster
sera déterminant (choix crucial, car il est en général très difficile de changer une fois les tables
en production).
Nous ne prendrons pas parti ici. Si on préfère en rester à l'identification absolue, on sera amené
à procéder comme dans le cas des entités-types indépendantes (cf. paragraphe 5.1.2), pour obtenir :
(0,n).png)
N.B. Dans le cas de l'identification absolue, si on utilise par exemple DB2 ou SQL Server,
la clé de l'index cluster sera de préférence composée de la colonne ClientId.
Comme on l'a évoqué, on peut donc aussi choisir d'utiliser l'identification relative :
.png)
N.B. Le DBA pourra préférer cette solution permettant de diminuer d'une unité le nombre d'index ;
en effet l'index « primaire » (PRIMARY) a pour clé le couple <ClientId, CommandeId>
tandis que l'index COMMANDE_CLIENT_FK a pour clé le singleton <ClientId> :
on a de nouveau affaire aux index redondants (cf. paragraphe 4.10) :
.png)
Rappelons à cette occasion que les valeurs prises par la colonne CommandeId sont relatives,
c'est-à-dire qu'elles sont obtenues par incrémentation, mais avec une numérotation de CommandeId
qui commence à 1 pour chaque client.
Voir le billet de
CinePhil
à ce sujet : «
Trigger pour incrémentation relative ».
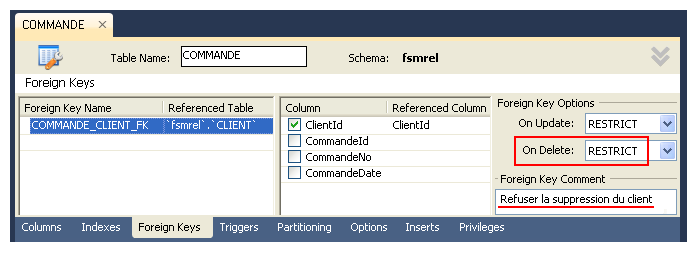
Rappelons aussi que la suppression d'un client doit être refusée si celui-ci a au moins une
commande, se reporter au paragraphe 10.4.6 pour ce qui a trait au métabolisme des données
(option ON DELETE) :
En tout cas, que l'on ait identifié COMMANDE de façon absolue ou relative, il n'y a pas à hésiter en ce
qui concerne les lignes de commande, car elles correspondent véritablement à une propriété (multivaluée)
de la commande (on peut aussi voir une ligne de commande comme une association entre une commande et
un produit).
Situation avant établissement de la relation entre COMMANDE et LIGNE_COMMANDE :
.png)
Situation après :
_apres.png)
Un index, à savoir LIGNE_COMMANDE_COMMANDE_FK, est à éliminer (cf. paragraphe 4.10),
car il a pour clé le couple <ClientId, CommandeId> inclus dans le triplet
<ClientId, CommandeId, LigneCommandeId>, lui-même utilisé pour la clé de l'index primaire de la
table LIGNE_COMMANDE (où — identification relative oblige —
LigneCommandeId est à numéroter relativement à <ClientId, CommandeId>) :
.png)
En ce qui concerne l'action compensatoire ON DELETE, elle est évidemment CASCADE puisque les lignes de
facture sont réellement des entités faibles (cf. paragraphe 1.3), ce qui oriente les choix
quant aux conséquences de la suppression d'une commande cf. paragraphe 10.4.6) :
.png)
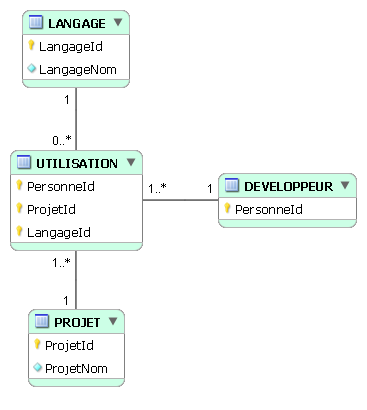
5-3. Retour sur les associations de plusieurs à plusieurs : associations ternaires▲
Le procédé utilisé pour les associations binaires vaut bien entendu pour les associations ternaires et
au-delà. Supposons qu'on veuille établir une telle association pour savoir quels langages de programmation
les développeurs de l'entreprise Dubicobit utilisent dans le développement des projets de la maison.
Situation initiale :
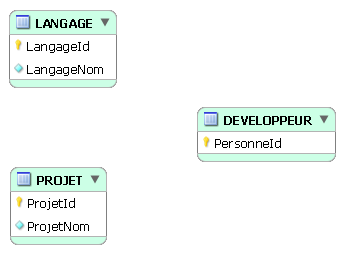
On définit la table servant à implémenter l'association ternaire, appelons-la UTILISATION :
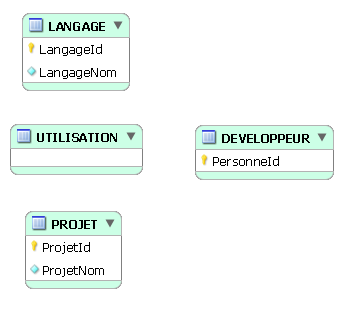
On établit un 1er lien identifiant :
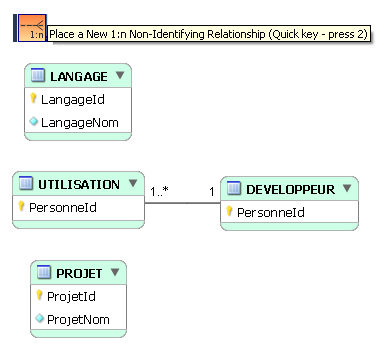
Puis on établit un 2e lien :
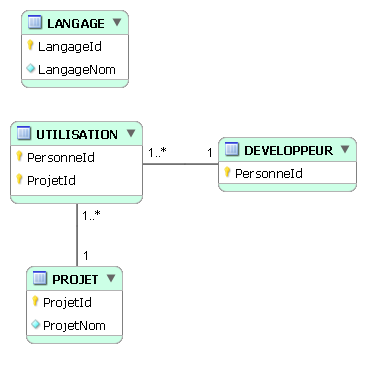
Et enfin le 3e lien :